I just checked with a clean 16.7.0, and I can’t reproduce your problem. Can you try to edit the XWiki.PDFExport.Sheet with the Wiki editor (you need to enable advanced user in your profile) and rename the outputMetadataFromTargetDocument Velocity macro. There should be two occurrences: one where the macro is called and another one where the macro is defined. Add some suffix to the macro name in both places. You can also write some text before and after the macro call, to see if it appears in the PDF export. Does it change anything?
{{velocity output="false"}}
#set ($sheetReference = 'XWiki.PDFExport.Sheet')
#set ($pdfElements = ['cover', 'toc', 'header', 'footer'])
#set ($pdfExportJobId = $request.jobId.split('/'))
#if ($pdfExportJobId)
#set ($pdfExportJobStatus = $services.job.getJobStatus($pdfExportJobId))
#set ($pdfExportJobRequest = $pdfExportJobStatus.request)
#else
#set ($pdfExportJobStatus = $NULL)
#set ($pdfExportJobRequest = $NULL)
#end
#macro (getPDFExportConfigFromRequest $pdfExportConfig)
#if ($pdfExportJobRequest)
#set ($discard = $pdfExportConfig.putAll({
'template': $pdfExportJobRequest.template,
'cover': $pdfExportJobRequest.isWithCover(),
'toc': $pdfExportJobRequest.isWithToc(),
'header': $pdfExportJobRequest.isWithHeader(),
'footer': $pdfExportJobRequest.isWithFooter()
}))
#end
#end
#macro (renderPDFSheet $pdfExportConfig)
#set ($discard = $response.setContentType('text/html'))
#set ($discard = $xwiki.ssx.use($sheetReference))
## Temporarily disable the JavaScript minification until we find a way to fix the following Closure Compiler error:
## [JSC_DYNAMIC_IMPORT_USAGE] Dynamic import expressions cannot be transpiled.
## See https://github.com/google/closure-compiler/wiki/JS-Modules#dynamic-import-expressions
## See also https://github.com/google/closure-compiler/issues/2770 ([FEATURE] Support dynamic import)
## This error is unexpected considering that we disable the transpiling here
## https://github.com/xwiki/xwiki-platform/blob/xwiki-platform-15.7/xwiki-platform-core/xwiki-platform-skin/xwiki-platform-skin-skinx/src/main/java/com/xpn/xwiki/web/sx/JsExtension.java#L91-L97
## We're using STABLE as input ECMAScript version, see https://github.com/xwiki/xwiki-commons/blob/xwiki-commons-15.7/pom.xml#L2585
## which is probably lower than ECMAScript 2020 (ES11) when support for dynamic imports was introduced.
## See also https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/import
## and https://caniuse.com/?search=import()
#set ($discard = $xwiki.jsx.use($sheetReference, {'minify': false}))
#set ($discard = $xwiki.ssx.use($pdfExportConfig.template))
#set ($discard = $xwiki.jsx.use($pdfExportConfig.template))
## Use the specified PDF file name as the title of the HTML page in order to have it suggested as file name when
## saving the PDF from the browser's Print Preview dialog.
#if ($pdfExportJobRequest)
#set ($title = $pdfExportJobRequest.fileName)
#end
## Output the HTML header but without the garbage from the start of the BODY tag.
#set ($htmlHeader = "#template('htmlheader.vm')")
## The PDF export doesn't target only the paper paged media, and we want to preserve the styles from the XWiki skin as
## much as possible.
#set ($htmlHeader = $htmlHeader.replace('data-xwiki-paged-media="paper"', ''))
#set ($headTagEnd = $htmlHeader.indexOf('</head>'))
#set ($bodyTagStart = $htmlHeader.indexOf('<body'))
#set ($bodyContentStart = $htmlHeader.indexOf('>', $bodyTagStart) + 1)
$htmlHeader.substring(0, $headTagEnd)
<script>
requirejs.config({
## When performing large multi-page exports the RequireJS timeout can be reached because there are many HTTP
## requests and the browser uses a limited pool to handle them. We noticed this problem on a PDF export with many
## live tables because they fetch their results pretty early, before many RequireJS modules are requested. In any
## case, we have the page ready timeout to stop the export in case it takes too much time to load the print preview
## page. We don't need another timeout for RequrieJS modules.
waitSeconds: 0,
## PagedJS uses some utility functions that are not exposed by the RequireJS module, so we have to import them
## ourselves from the WebJar in order to be able to patch PagedJS bugs.
config: {
'pagedjs-module': {
baseURL: $jsontool.serialize($services.webjars.url('org.webjars.npm:pagedjs', ''))
}
}
});
</script>
## Inject the required skin extensions.
$!pdfExportJobStatus.requiredSkinExtensions
#clientSidePDFExportConfiguration()
## Start the BODY tag.
$htmlHeader.substring($headTagEnd, $bodyContentStart)
#set ($pdfTemplateObj = $xwiki.getDocument($pdfExportConfig.template).getObject('XWiki.PDFExport.TemplateClass'))
#foreach ($element in $pdfElements)
#if ($pdfExportConfig.get($element))
#set ($output = "#renderPDFElement($pdfTemplateObj $element)")
#set ($output = $output.trim())
#if ($output != '')
<div class="pdf-$element">$output</div>
#end
#end
#end
<div id="xwikicontent">
#renderPDFContent()
</div>
## Close the tags opened in htmlheader.vm
</body>
</html>
#end
#macro (clientSidePDFExportConfiguration)
#set ($clientSideConfig = {
'documents': [],
'baseURL': $pdfExportJobRequest.baseURL
})
#foreach ($renderingResult in $pdfExportJobStatus.documentRenderingResults)
#set ($discard = $clientSideConfig.documents.add({
'reference': $services.model.serialize($renderingResult.documentReference, 'default'),
'idMap': $renderingResult.idMap
}))
#end
<script id="pdfExportConfig" type="application/json">$jsontool.serialize($clientSideConfig).replace(
'<', '\u003C')</script>
#end
#macro (renderPDFElement $pdfTemplateObj $element)
#unwrapXPropertyDisplay($tdoc.display($element, $pdfTemplateObj))
#end
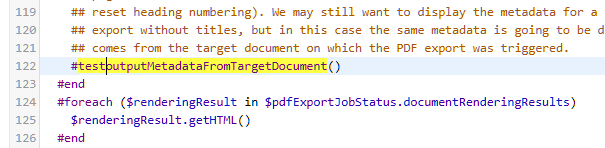
#macro (renderPDFContent)
#if (!$pdfExportJobRequest.isWithTitle())
## The document renderer includes the document metadata in the rendering results only when document titles are
## displayed (because we should have a single metadata on a print page and the document title starts on a new print
## page, but also because the metadata can be used to tweak how the document title is displayed, e.g. to skip or
## reset heading numbering). We may still want to display the metadata for a single page export or for a multipage
## export without titles, but in this case the same metadata is going to be displayed on all print pages, and it
## comes from the target document on which the PDF export was triggered.
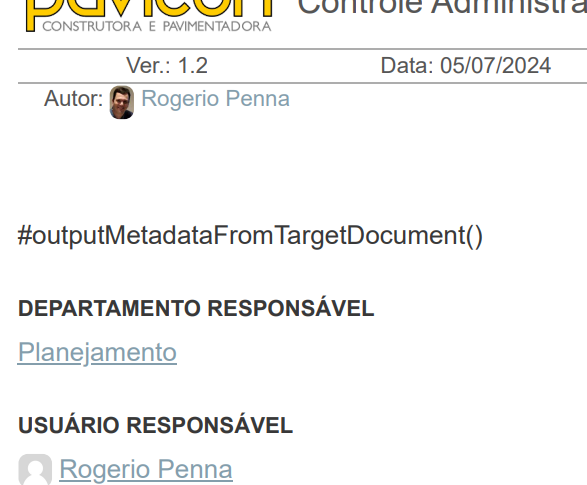
#outputMetadataFromTargetDocument()
#end
#foreach ($renderingResult in $pdfExportJobStatus.documentRenderingResults)
$renderingResult.getHTML()
#end
#end
{{/velocity}}
{{velocity wiki="false"}}
#if ($request.sheet == $sheetReference)
## Default PDF Export configuration.
#set ($pdfExportConfig = {
'template': 'XWiki.PDFExport.Template',
'cover': true,
'toc': true,
'header': true,
'footer': true
})
#getPDFExportConfigFromRequest($pdfExportConfig)
#renderPDFSheet($pdfExportConfig)
#end
{{/velocity}}
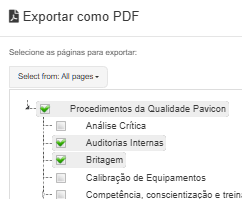
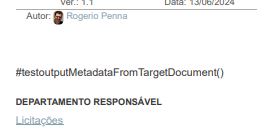
based on the code in that part, I don´t really understand what it does. If the document is without title, it should should CALL that function and show the title there.
but the document HAS a title, it’s even being shown in the header.
Since it’s showing the text there, what if I delete the text?
the help text on " https://extensions.xwiki.org/xwiki/bin/view/Extension/Extension+Manager+Application#HComputeChanges " to compute changes is very bad. Where do I post suggestions to improve it? The help should show an image that you must click on the arrow next to uninstall to see the “Computer Changes” option. And then click the tab Changes. The image in the help doesn´t show the changes tab NEITHER the Compute Changes option