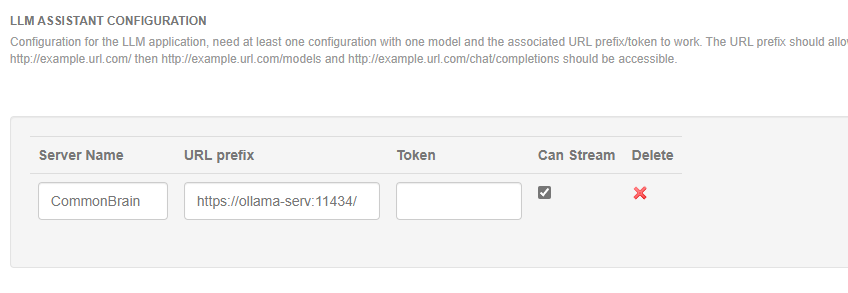
Ollama by default offers the OpenAI-compatible API at /v1/, not at the root. Are you sure that server configuration is correct? I would suggest trying https://ollama-serv:11434/v1/ as URL. If this doesn’t help, have you checked your XWiki server’s logs?
If I curl with :
curl -X POST “https://ollama-serv:11434/v1/chat/completions”
-H “Content-Type: application/json”
-d ‘{
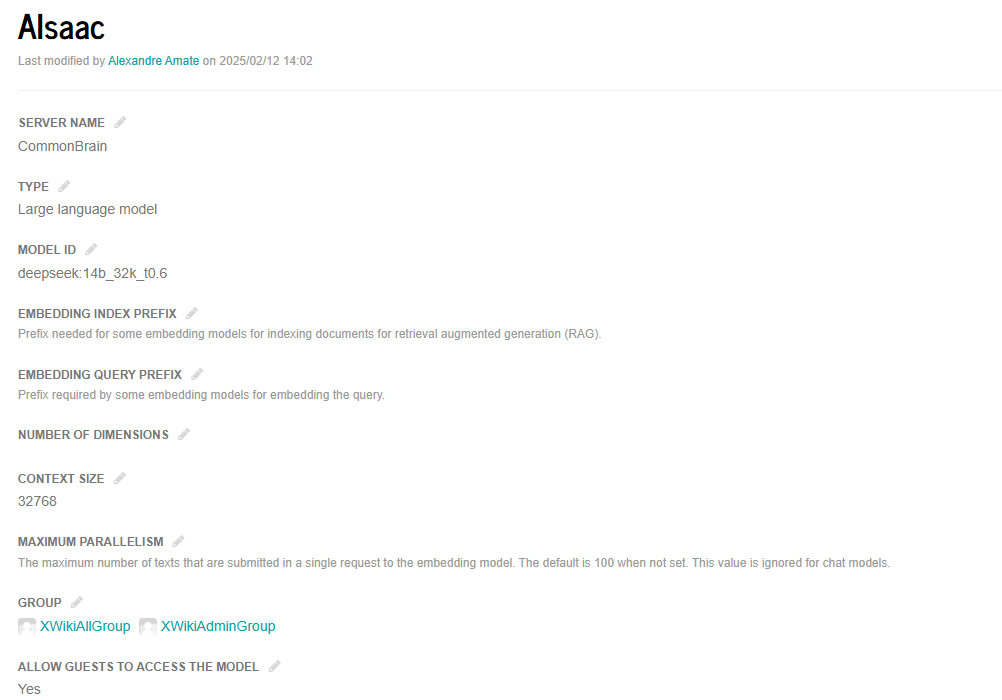
“model”: “deepseek:14b_32k_t0.6”,
“messages”: [
{“role”: “system”, “content”: “You are an AI assistant.”},
{“role”: “user”, “content”: “Hi, how are you?”}
]
}’
I get an answer so it should be good:
{“id”:“chatcmpl-272”,“object”:“chat.completion”,“created”:1739373942,“model”:“deepseek:14b_32k_t0.6”,“system_fingerprint”:“fp_ollama”,“choices”:[{“index”:0,“message”:{“role”:“assistant”,“content”:“\u003cthink\u003e\nAlright, someone just said "Hi, how are you?" to me. I need to respond in a friendly and approachable way.\n\nI should acknowledge their greeting and let them know I’m here to help.\n\nSince I’m an AI, I don’t have feelings, but I can express that I’m ready to assist them today.\n\nKeeping it concise and warm is key.\n\u003c/think\u003e\n\nHi! I’m just a computer program, so I don’t have feelings, but thanks for asking! How can I assist you today?”},“finish_reason”:“stop”}],“usage”:{“prompt_tokens”:15,“completion_tokens”:108,“total_tokens”:123}}
XWiki isn’t using curl to talk to Ollama. In the log you might see an error message that gives you more information why the request fails. Also, try disabling streaming in the configuration with the Ollama URL as non-streaming responses are easier to debug, and you might see more information about non-streaming responses in the browser’s developer tools which is another place I would suggest to look for hints what the problem is.
The LLM integration is really a beta, and we haven’t put that much work into providing useful error messages and diagnosing information for error cases.
This doesn’t look like XWiki’s log but the web server’s log. Please find the log of XWiki. What you can see in that log that you pasted is basically the same as what you saw in the UI: XWiki replies to the chat completion request with an error (error 500, so internal server error). I think I added error logs to log basically all errors but if there is really nothing in the logs, you could also try if you can get the response body of that request from the browser’s developer tools. As I’ve mentioned, getting these response bodies usually works much better with streaming disabled, at least I couldn’t see anything in the browser with streaming enabled.
Hi @Amatatouille ,
did you manage to resolve your issue?
In my case it seemed that my AI server did not support Http2 requests and Xwiki is sending an Upgrade header.
To figure that out, try to call you LLM server with some rest client and if that works add the headers that Wiki is adding