I am looking to setup XWiki on two machines and sync periodically between the two. eg. office and home.
Ideally I would like some sort of patch generated that I could apply to the other instance.
What are my options and how do I get started?
1 Like
That looks like the XWiki Concerto research project of a few years ago but it didn’t end into something usable:
What about exporting the data via the Restful APIs and then pushing it into the other instance, or is it an overkill?
- would the rest API provide the complete data?
- is pushing the data into the other instance feasible?
Yes that should work fine.
Interesting topic … maybe due to the lack of imagination by me, how would you define “sync periodically”?
Office => Home or Office <=> Home or Home => Office
Regards
Beat
As far as I remember, one of the reasons why Concerto was dropped was that similar results could be achieved with database replication.
You might want to look into mysql database replication (synchronization) so that you don’t have to do anything on the XWiki side, but synchronize the underlying SQL database instead. There should be enough tutorials available online on the topic.
Let us know how it goes 
What I remember was that the issue is that the algorithm used was able to do merges without conflicts of various nodes (that’s one important part) but it couldn’t be guaranteed how long it would take for all nodes to sync and this could take a lot of time.
The idea of sync periodically between the two instances is via a third copy of the data. So you would have three repositories, Home (A), Office (B) and USB or remote server ©.
For example, you add a page or make a modification to a page at A. You then sync this with C and then C to B. Since it is manual, you’re prone to forget. So every few days when you do sync you face the problem of conflicts. Git, the version control repository can be used in this manner and then you resolve conflicts at the point of sync. MLO, a todo list manager also has a similar feature and presents a list of tasks which have been modified in two places. Since xwiki has versioning like Git, the data from both places could be stored.
@lightbender
Typically you try to avoid syncing due to all the issues and complexity - using a web technology accessible from everywhere
Regards
One of the objective of Concerto was to be able to take xwiki instances offline and when they joined the network again they’d sync their database contents. Are you sure this can be achieved with database replication?
I’ve got the similar problem, that I would like to work offline with my local XWiki on the laptop and sync with a server when back in the net. I’m going to give symmetricDS a try, but would like to know before, how XWiki will behave when data are modified directly on the database. Will the cache notice? If not, will it notice after restarting the servlet container, or are there any persisted cache components that would survive?
Thanks
Guido
No persistent cache to worry about for this use case. Solr index is kind of a persistent cache but it’s making sure automatically at startup that it’s up to date.
Something you will have issue without if you just synchronize databases is extensions since they are not stored in the database (some extension need to be loaded before the database is initialized). So you might also need to synchronize the permanent dir if you plan to play with extensions too.
Thanks! Didn’t think of that. I’ve just checked: symmetricDS supports file synchronization as well. So it might be a solution. I’ll try and set that up.
Jumping in to say that I am working on a similar set up, checking in to see if you’d had an luck since you last posted.
Working with MySQL replication, just Master-Slave for now. Database replication is working fine as confirmed by inspecting using MySQL workbench, but I’m still working on getting the clustering to work properly so that the cache’s are synchronized.
My desired setup is a little bit different than the classic cluster scenario. I am not looking to load balance, but use discrete server / DB units to provide localized access at remote sites while maintaining everything in a single Master database.
If I have any success I will report back.
As for the caching issues, no errors are being thrown from JGroups so far. Currently testing a with tcp channel targeting two locally hosted tomcat instances. One instance is connected to the Master DB, while one is connected to the Slave DB. Next step is to verify clustering works with both servers connecting to the same database, as suggested in the Clustering guide. Will try UDP channel as a second resort as well.
My setup details are below:
XWiki 9.11.7
Tomcat 7.0.90
Java 1.8.0_172
Hello @muhsackio,
Sounds interesting, I was thinking of something similar in future so would be interested to know how you get on.
Is your proposed setup anything like sharding?
Thanks,
Ben
My proposed setup isn’t quite like sharding. My goal isn’t to distribute load in a high traffic environment, which sharding seems to address based on my understanding. It is instead to provide data consistency across instances which may be hosted in disparate geographic locations with poor / expensive internet connectivity. We host in these remote locations to provide quicker access to users to who are affected by poor internet connectivity, but the challenge is to provide them with a data set consistent with what it is on our main site.
Here is a diagram of what this would look like:
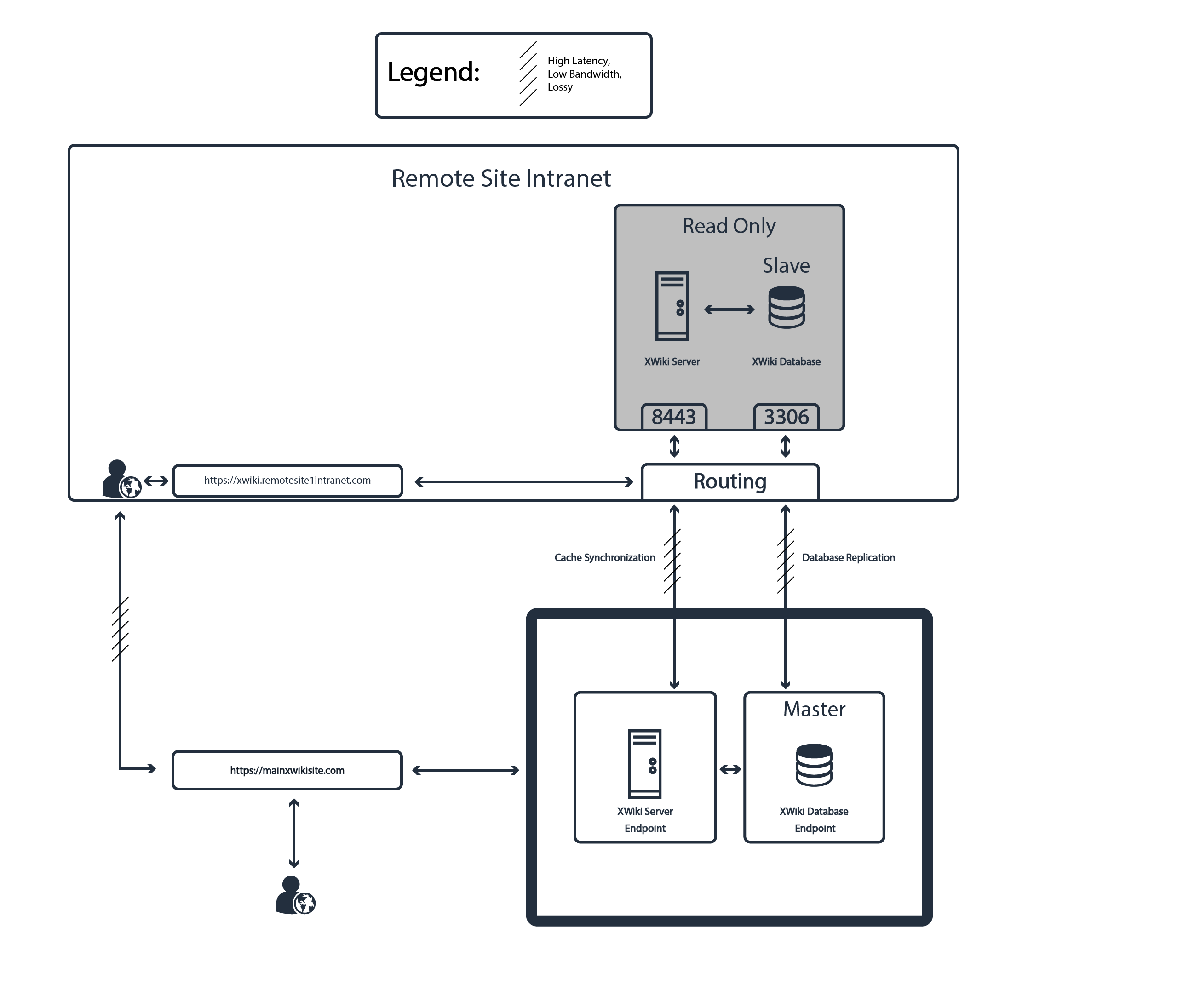
Provided I can get a Master - Slave setup to work, a Master-Master setup would be next to enable write capability at the remote site.
If the connection is not very good but normally at least available, you might check out the “Clustering Guide” as a start: https://www.xwiki.org/xwiki/bin/view/Documentation/AdminGuide/Clustering/
As the “shared file system” needed for that solution is likely not an option here, you might use a different solution like regular calls to rsync between the instances.
Did you have any success? I’m looking to do exactly what you’ve described and have it working except the remote XWiki’s isn’t showing the revised documents which is due to caching. Once I solve this issue I think I’ll have a working solution.
No, sorry, @danthi, I never took the time to set this up.