first of all I am running a XWiki version 12.10.6.
I am writing my documentations in german actually and thats why the umlauts are needed for me in specific cases.
I want to add a text anchor in order to link to it from other points of the document or even completely different pages. Therefore I am using headers because they automatically create an anchor.
When this header / anchor contains a german Umlaut then it seems to me that the anchor function doesnt work properly.
In this case I wanted to write the word “ausgewählt” and then add a link to the anchor but this didnt work.
When I replaced it with “ae” instead of “ä” then it worked.
When I tried to replace the “ä” with html encoded string it didnt work.
Am I doing anything wrong with Umlauts or is there a problem in this version while using anchors?
MaDo, although I’m german speaking - as IT company - we write all our documentation in EN … anyway, one option that comes to my mind: if you add a TOC (Table of contents) to such a document, I assume clicking the link in the TOC will work (automatic anchor). If this is the case, then you can inspect the URL to see what the anchor was. If the TOC does not work, I suggest to create a Jira
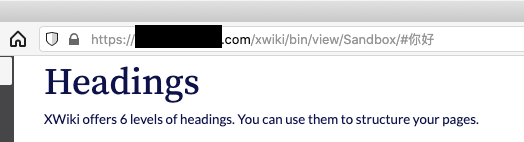
When I cut and pasted the url to another window, the utf8 characters were automatically urlencoded.
e.g. https://example.com/xwiki/bin/view/Sandbox/#这个
became https://example.com/xwiki/bin/view/Sandbox/#%E8%BF%99%E4%B8%AA
Thanks for your input @Beat_Burgener and @pdwalker.
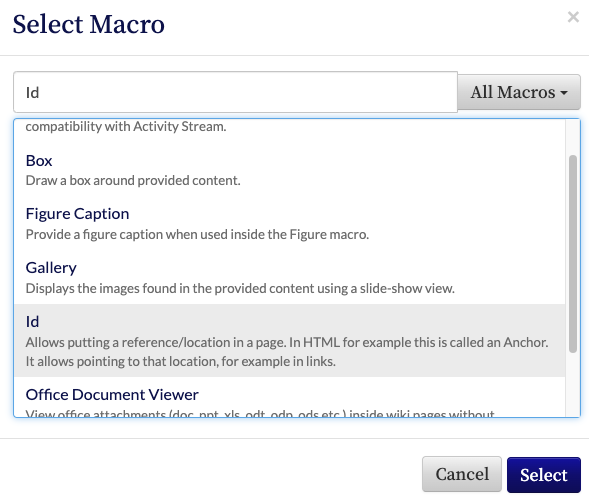
Unfortunately I am not that familiar with xwiki yet. And I dont even know how to access the xwiki source editor or how to use an ID macro on xwiki.
I just gave it test. What xwiki does with the characters is convert them into their unicode representation. In this case Ü = unicode U+00DC or “DC” which you can see on the string.
So if you have a header with Überschrift and try to use the anchor of #HÜberschrift, it will fail, but #HDCberschrift will work.
If you specifically want the Ü character as part of the anchor, then you have to do it by hand by using the anchor macro.
This is working as expected as the feature is designed for HTML 4/XHTML 1.0 where ids must not contain any non-ASCII characters (see the specification for the details). In HTML 5, no such restrictions exist, there the only requirement is that the id contains at least one character and no ASCII whitespace.
We could discuss extending the allowed characters in the generator of automatic ids to in particular include all non-ASCII characters (other ASCII characters are problematic as most of them have some special meaning and would require escaping in many contexts). However, there is a huge problem with backwards-compatibility: If you have any links to the old ids, these links will break when the generator is updated. And there is no possibility to assign two ids to an element. It might be possible to design some automatic migration that tries updating links based on a mapping from old to new ids (by generating ids with both generators and comparing them) but this is far from trivial. It is certainly also possible to make this configurable and to default to the new implementation for new installations. Feel free to open a Jira issue for this improvement but unless somebody sponsors the development there is no guarantee this will be implemented.