We, AutomationX, are using XWiki as an Intranet interally (meeting protocols, blog post news, internal information) as well as a knowledgebase / software documentation plattform for our products for both, external customers as well as our co-workers who use the software.
The following is a work in progess brainstorming 
(0) Make common tasks dummy-user friendly
You are already working on this This means enabling WYSIWYG experience for most daily tasks (autocompletion of stuff like links etc. etc.) which has greatly improved recently. Time has shown us that most of the users are in no way willing to learn xwiki syntax or anything in that direction, everything has to be a kidsfriendly-applike-facebook-instagram difficulty 
The following to things are the only BIG issues we face, which are still unresolved in XWiki 10.10 for us.
Our customers often demand “offline documentation”, like something they can print out (for real)
Issues (1) und (2) are somewhat mitigated by the greatly improved HTML Export, so maybe we should scrap PDF and focus on HTML completely (they can carry it on USB and save some trees)
(1) PDF Export looses formatting
If you export the Sandbox Page to PDF in latest xwiki 10.10, it looses lots of formatting. I don’t know if this is a limitation of PDF / OpenOffice? If I copy paste it from Firefox to M$ Word 2013, it has some of the same issues. Exporting has improved a lot since xwiki 8.4.3 though
- Info / Warning / Error / Success Box Macro or Style is lost, this is vital information in the docs. The only thing thats preserved is Background Color via CKEditor Toolbar.
{{code}} Macro Syntaxhighlight does not use monspaced font in PDF- Tables have formatting problems if there is to much stuff
- Tables look ugly in PDF (can probably be tweaked)
Is openoffice used for the pdf export? I had noticed Libre Office does a better job on importing office. Since the docker images contains openoffice, I haven’t used libre office in a while.
(2) Easy export of multiple pages (spaces) to PDF not possible
The was the greatest loss when we ditched mediawiki, since that had the export to book feature, which rendered a really nice pdf for several pages.
As far as I can tell, none of the available PDF export solutions for xwiki work satisfactory.
Maybe there is some browser extension which could help us.
Does the job and is easy to use, but if you export multiple (child-)pages, everything is crammed together:
- Page Head on each page shows the Title of the page where wo startet the export, even if you use Page Breaks and the PDF page shows a Child page
- Childpages have no title introducing them, you would have to use a Heading 1 yourself on every page.
- The TOC at the beginning also shows all headings of all child pages on the same level
- Saving of collections sometimes gets stuck at 0%
- Exporting a collection to pdf renders a pdf with only exception callstacks:
org.xwiki.rendering.macro.MacroExecutionException: Failed to evaluate Velocity Macro for content
(3) Improving HTML Export
HTML Export of spaces is pretty great! It looks exactly like the live version, and retains relative page links so you can user links to navigate between offline documents.
(3.1) Render Macros in HTML Export (3)
We heavily rely on the {{children}} Macro for navigation, since manual hyperlinks are time-consuming. These are not rendered in HTML export, in contrast to e.g. the {{toc/}} macro.
It would be great to optionally execute all macro content during HTML export, and save the macro output in the export. This would be sufficient for our cases I guess.
The same goes for the Navigation Panel and Breadcrumb dropdown menu, but this is lower priority.
(3.2) Customize HTML Export Layout
In offline HTML the following elements should be excludeable / customizeable , to show only Pagecontent in the export:
- Hide Left and/or Right Columns of Main Page Layout (online show content)
- Hide Page Buttom Layout: shows Tabs for Comments; Attachments; History; Information: None of them are working.
- Hide Actions:
- Hide Global Site Header stuff: Search / Notifications Button / UserProfile / Hamburger Menu Button
(4) Page Auto Translation
We are currently writing all our content in German. Manually maintaining everything also in English is unmanageable for us. We use a custom Panel with a google translate widget, which works fine for viewing single pages.
But this is not usable when using PDF (1 & 2) or HTML (3) Offline Export. I’m not aware of any xwiki extension aiding in that. Maybe there is some browser extension which could help us.
[EDIT]: to clearify, the task is to either:
-
a) automatically translate content of several pages to english in the course of exporting them to PDF or HTML, which would have to be done on the server side.
-
b) Translate complete spaces of xwiki pages in a batch job and store the results in english translations of these pages. THEN export the pages to PDF or HTML using the English content.
Other points:
This extension is great! In my opinion the best one to easily improve content navigation and visualisation. Tags are too easly overlooked and are meant for a different purpose.
- In the Future section is says “Automated creation of relations when page links are detected in the content.” : This would be very helpful, but should be optional, since there may be lots of links, some of which you may not want to add as relation.
- Since this extension relies on attached objects: does it scale? If there are > 1000 Pages and each of them has several relations?
Improving Search Experience
Repeatedly some of our users complain about the search function. Most of the time it is PEBKAC , like not using a * wildcard or using wrong key words in general. I haven’t deep dived into Apache SOLR configuration yet.
Maybe there can something be done to make search more “Google like” ?
- Searching
ServiceAccess does not match Pagename ServiceAccessMethod
- Search
Benutzer Verwaltung does not match Pagename Benutzerverwaltung
Improve Page Print Layout
Some users still want to actually print out pages. If you Print a xwiki page (to pdf or to paper), the layout contains some ugly elements, which are mostly undesired IMHO (could depend on user needs).
The printed layout looks better then the current Export to pdf result.
The default layout could be improved by the following points. Typically, the users wants to print CONTENT, and content only.
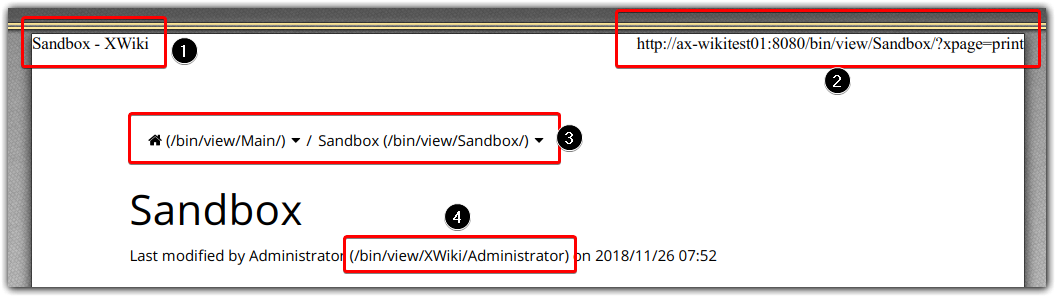
Example is XWiki Sandbox Page, PDF via Foxit PDF Printer:
-
Page Titel is an the far top left side, und therefore cut off on some printers, this should be centered (?) in the header
-
Top right side shows ugly url
-
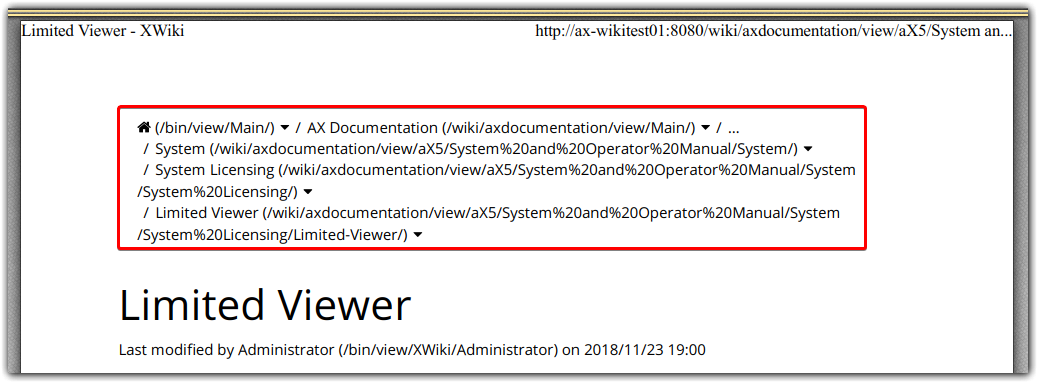
and 4.) All hyperlinks are rendered twice (probably intentional), label and url. If you have a deep hierarchy, the breadcrumbs can get huge, see following screenshot:
Breadcrumbs may print as label only, or be hidden by default.
-
The page bottom shows TAGs and Comments, even if there are none. Show tags only if they exist, hide page comments by default.
For the time being, thanks a lot.
BR Mario